As I mentioned in the previous post, Data warehouses are for data analysis, which is becoming a hot topic these days. So, in this post, let me explain about Data Marts which are part of data warehouse.
A data warehouse can have many data marts, and each data mart can answer one general analytics question. Data from various sources are cleaned, and prepared in well-structured data warehouse. However, these cleaned yet raw data cannot explain the business questions. Therefore, transforming data into information is required and this is where raw data from data warehouse is converted into meaningful information which will be stored in the data mart.
Usually, each data mart has one data schema. In each schema, there is one fact table and multiple dimension tables. The fact table contains the measures for business question and the dimension tables are the dimensions for the measure from the fact table.
There are 2 types of data schemas: Star schema and Snowflake Schema.
Star Schema

Star schema is simple. so it is fast in loading data. However, it is impossible to use hierarchical dimensions. Since the hierarchy is not allowed, the data contains duplicates.
For example, compare these 2 data of sales at a departmental store.
order001 | $23.9 | Branch A | New York | USA
order002 | $99.99 | Branch B | New York | USA
The location data is duplicated. If there are a lot of branches in New York, and as well as in the whole USA, there will be a lot of New Yorks… and USA, which takes a certain amount of space in each data line.
Snowflake Schema
The snowflake schema is like its name says, it is in snowflake shape with branches for the hierarchies.
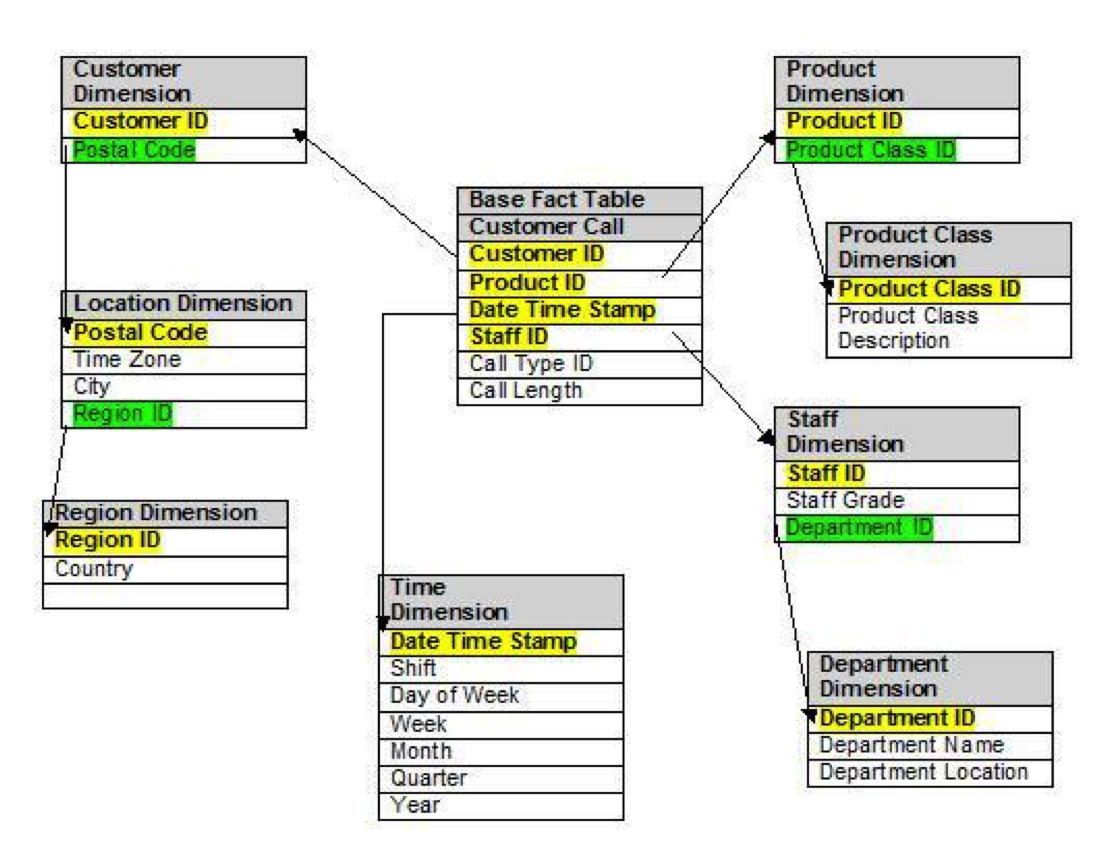
It basically saves the space of data like New York and USA in the previous example. So, it will save space. However, it has primary keys to link to hierarchical dimensions. This will delays the response time because of joints but there are less data to go through.
So, which schema to use and which is better?
My only ansewer is depends.
it is based on the business needs and nature of your business question that this fact table has to answer. So, if the requirement is only the general questions, star scheme is a better choice but again it just depends on how you will use this data mart.
Hope this post explains you well. If you have any question, please email me or comment below.

